[논문리뷰] Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision
2021년 06월 12일
프레임워크
Framework of cross pseudo supervision
방법
- 레이블이 있는 데이터는 supervised setup으로 학습하고
레이블이 없는 데이터는 한 데이터를 두 개의 모델에 통과시키고
각 예측값을 교차하여 stop gradient를 해주고 서로 다른 모델의 수도 레이블로 간주하여 학습한다. -
loss는 다음과 같다.
$\mathcal{L} = \mathcal{L}_{s} + \lambda \mathcal{L}_{cps}$
supervised loss $\mathcal{L}_s$와 cross pseudo supervised loss $\mathcal{L}_{cps}$의 합으로 구성된다.
Cross pseudo supervision는 unlabeled 뿐만아니라 labeled 데이터에 대해서도 수행하기 때문에 loss는 $\mathcal{L}_{cps} = \mathcal{L}_{cps}^{l} + \mathcal{L}_{cps}^{u}$이다. - Semi supervised learning을 위해
두 개의 모델을 이용하거나 Stop gradient(//)을 이용한 비슷한 연구와 비교하였다.
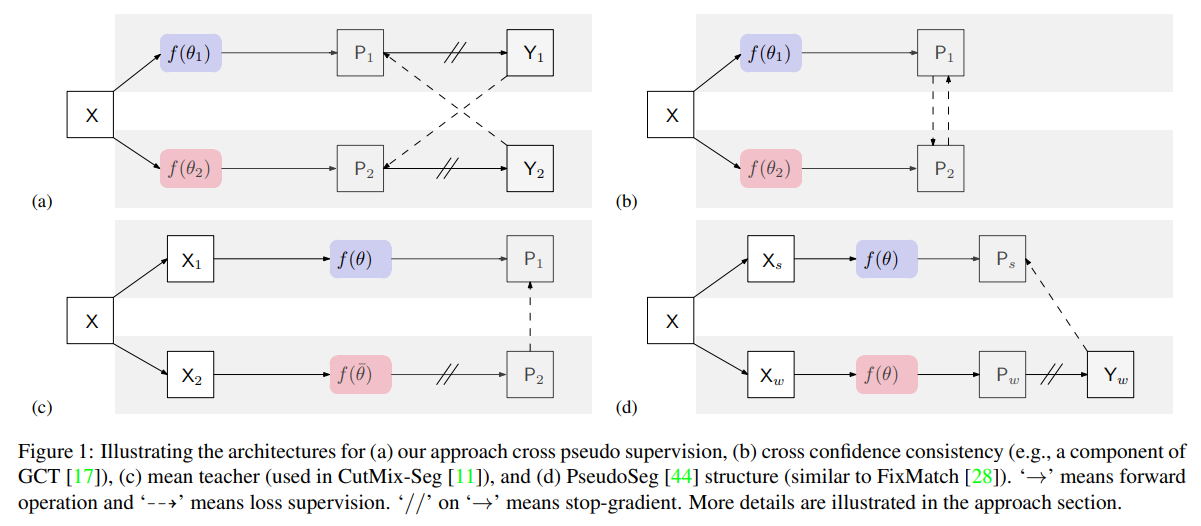 Comparison with related work
Comparison with related work이 중 (c) student와 teacher를 활용하여 teacher를 student의 average로 업데이트하는 방식보다 더 잘 된다는 것이 놀라웠다.
왜냐하면 보통 weight averaging을 통해 학습하는 것이 좀 더 general한 결과를 만들기 때문에 퍼포먼스 향상이 꽤 보장된다.(궁금하다면 Stochastic Weight Averaging에 대해 검색해보길 추천한다.)
그런데 이런 average 방식 없이 훨씬 간단하게 두 모델의 아웃풋을 cross하여 label로 SGD 하는 것이 더 나은 결과를 만들었다는 점이 인상적이다. 하이퍼파라미터도 추가되는 것 없이 다른 semi-supervised setup에서도 사용되는 loss 사이의 가중치($\lambda$)만 있기 때문에 여러 도메인에 안정적으로 적용하기 쉽다.
결과
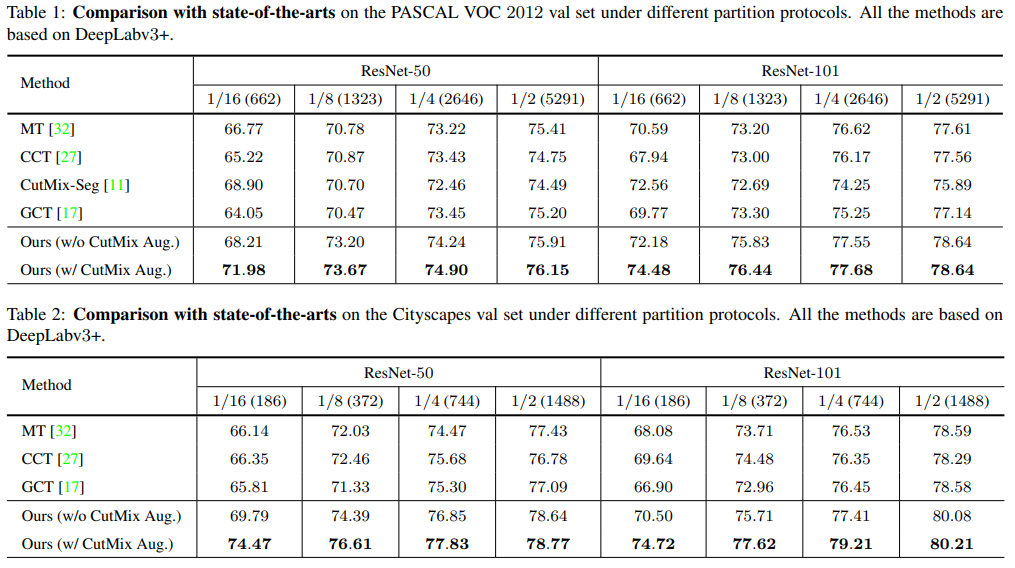
- PASCAL VOC 2012 val과 Cityscapes val에서 모두 SOTA를 달성하였다.
- CutMix를 결합하여 정확도를 조금 더 끌어올렸다.
Reference
- Xiaokang Chen, Yuhui Yuan, Gang Zeng, Jingdong Wang
Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision
https://arxiv.org/abs/2106.01226